x86 Architecture Fundamentals
Table of Contents
x86 Architecture Fundamentals
Number Systems
There isn’t much to say about binary here. What needs to be mastered is using short division to convert decimal -> binary. Then understand how logic gates implement addition.
Endianness
Program Execution Flow
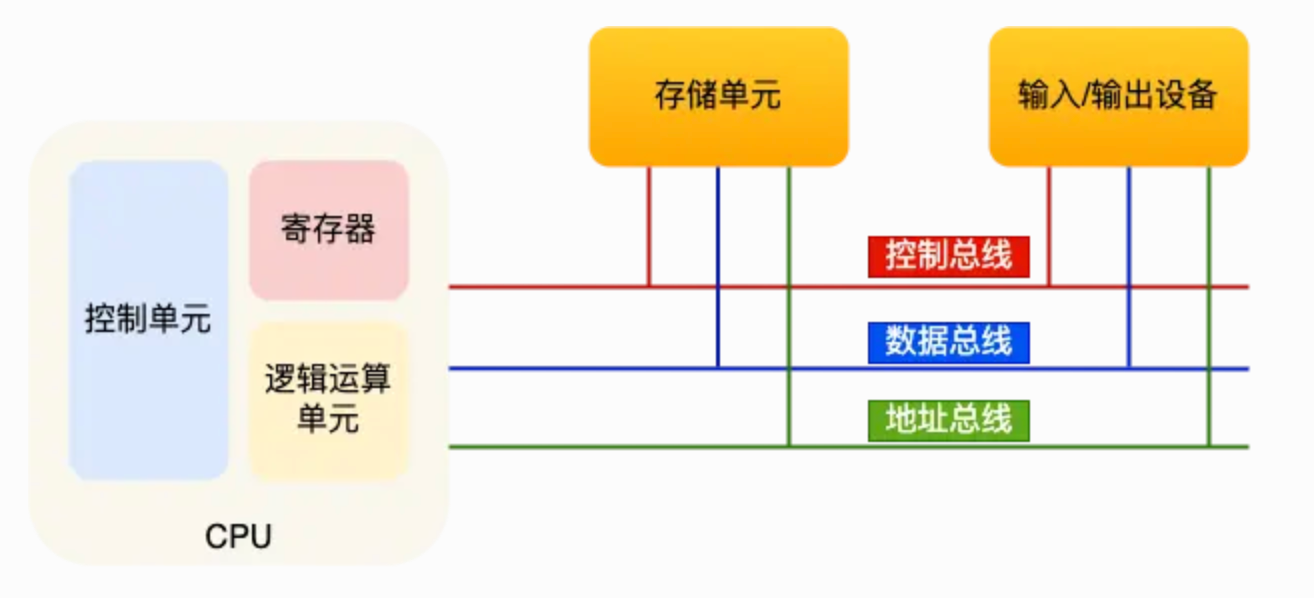
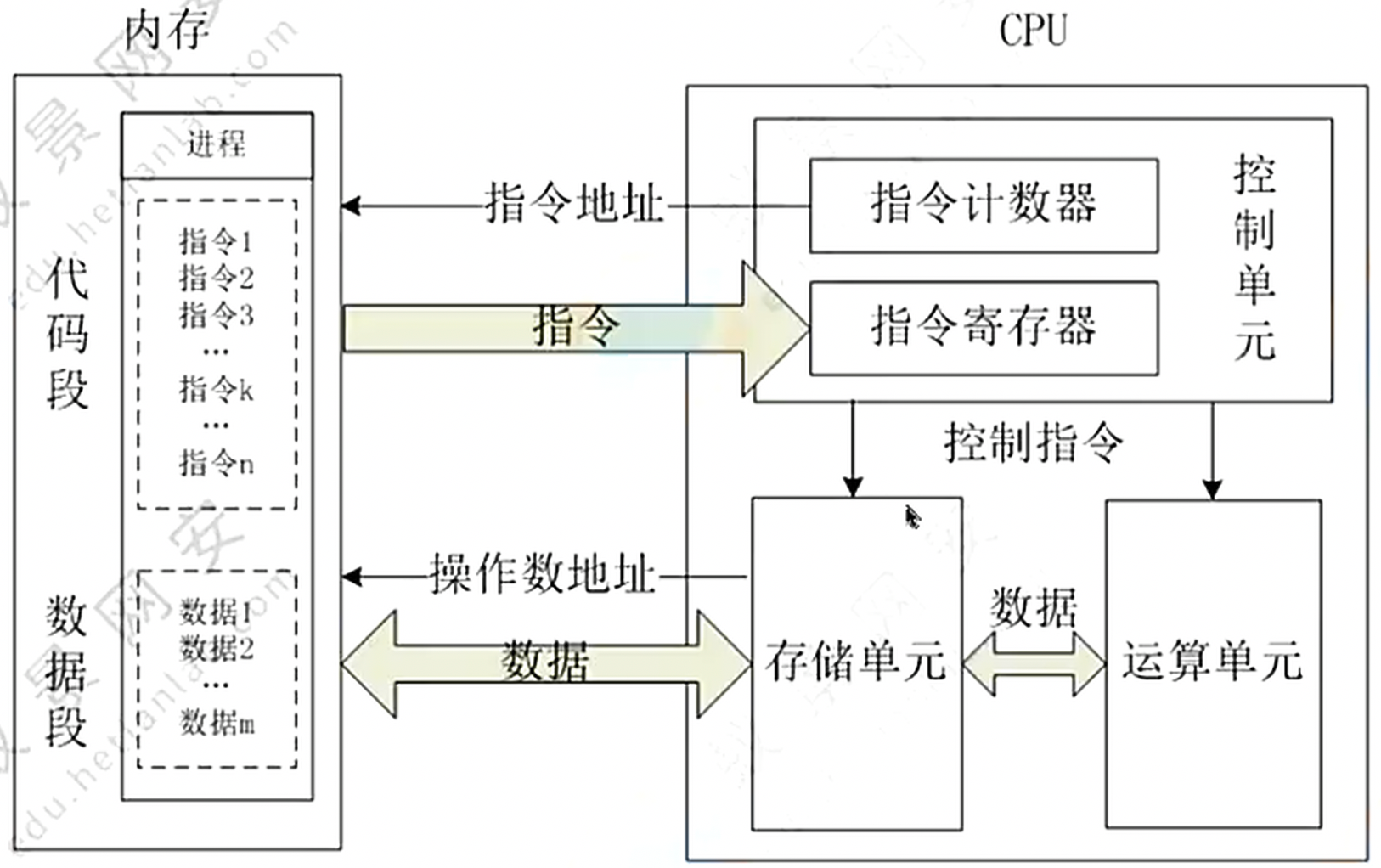
Data Storage
Immediate
Registers
The registers included in x86-32 are:
-
4 data registers (EAX, EBX, ECX, and EDX)
-
2 index registers (ESI and EDI)
-
2 pointer registers (ESP and E昭P)
-
6 segment 奇 registers (ES, CS, SS, DS, FS, and GS)
-
1 instruction pointer register (EIP)
-
1 flags register (eflags)
-
9 control registers (CRO-CR8)
-
3 protected-mode registers (GDTR,LDTR,IDTR)
Stack
Heap
Process Memory Layout
Assembly Instructions
NOP(nop)
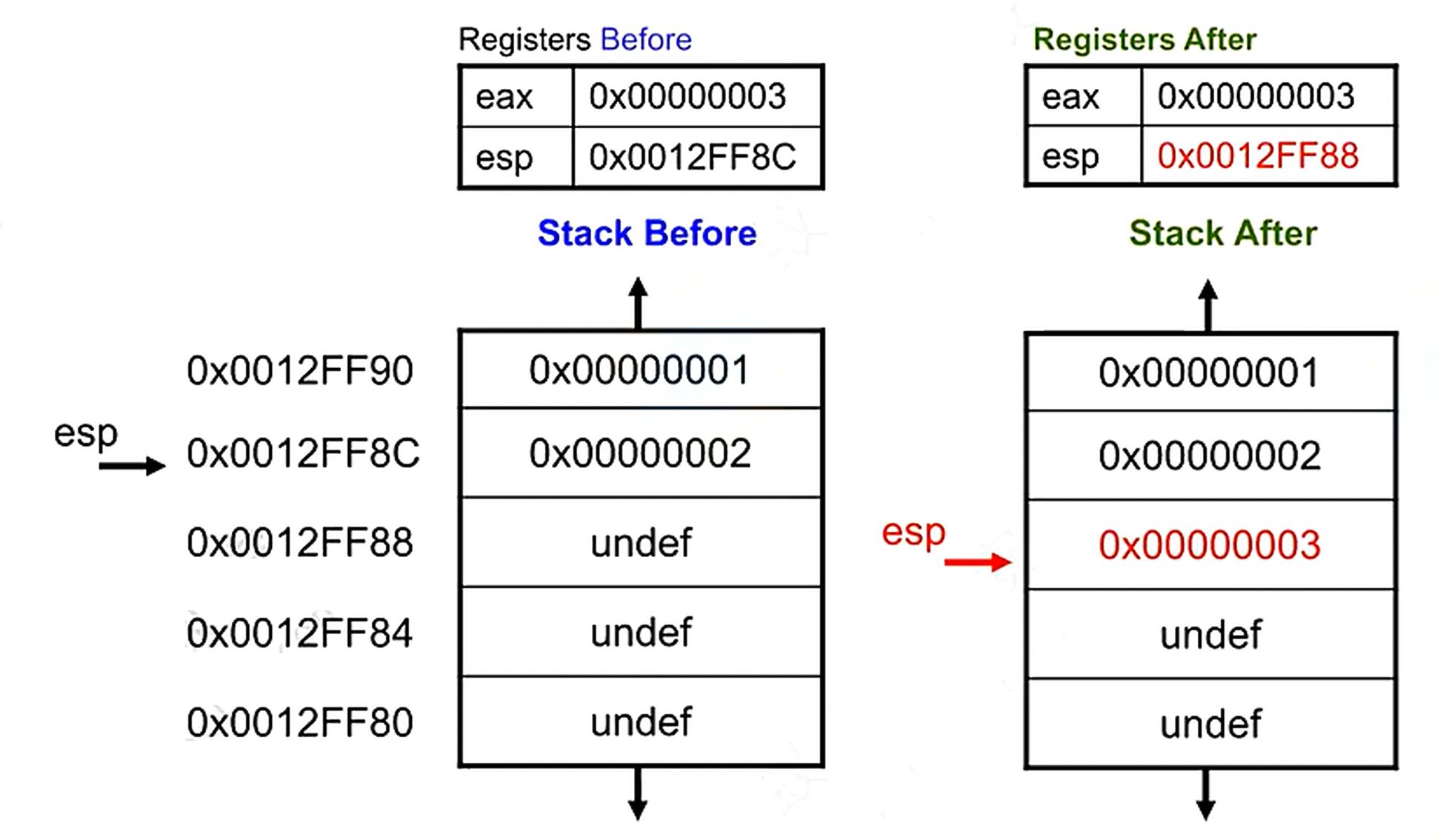
PUSH(push)
The PUSH instruction pushes data onto the stack.
The instruction format is pushX.
xajEX imm8, imm16, imm32, k/m16, r/m32, r/m64.
The stack pointer register ESP (RSP) is automatically decremented.
eg: push eax
POP(pop)
The POP instruction pops data from the stack.
The instruction format is popx.
× PJEX r/m16, г/m32, r/m64.
The stack pointer register ESP (RSP) is automatically incremented.
eg: pop eax
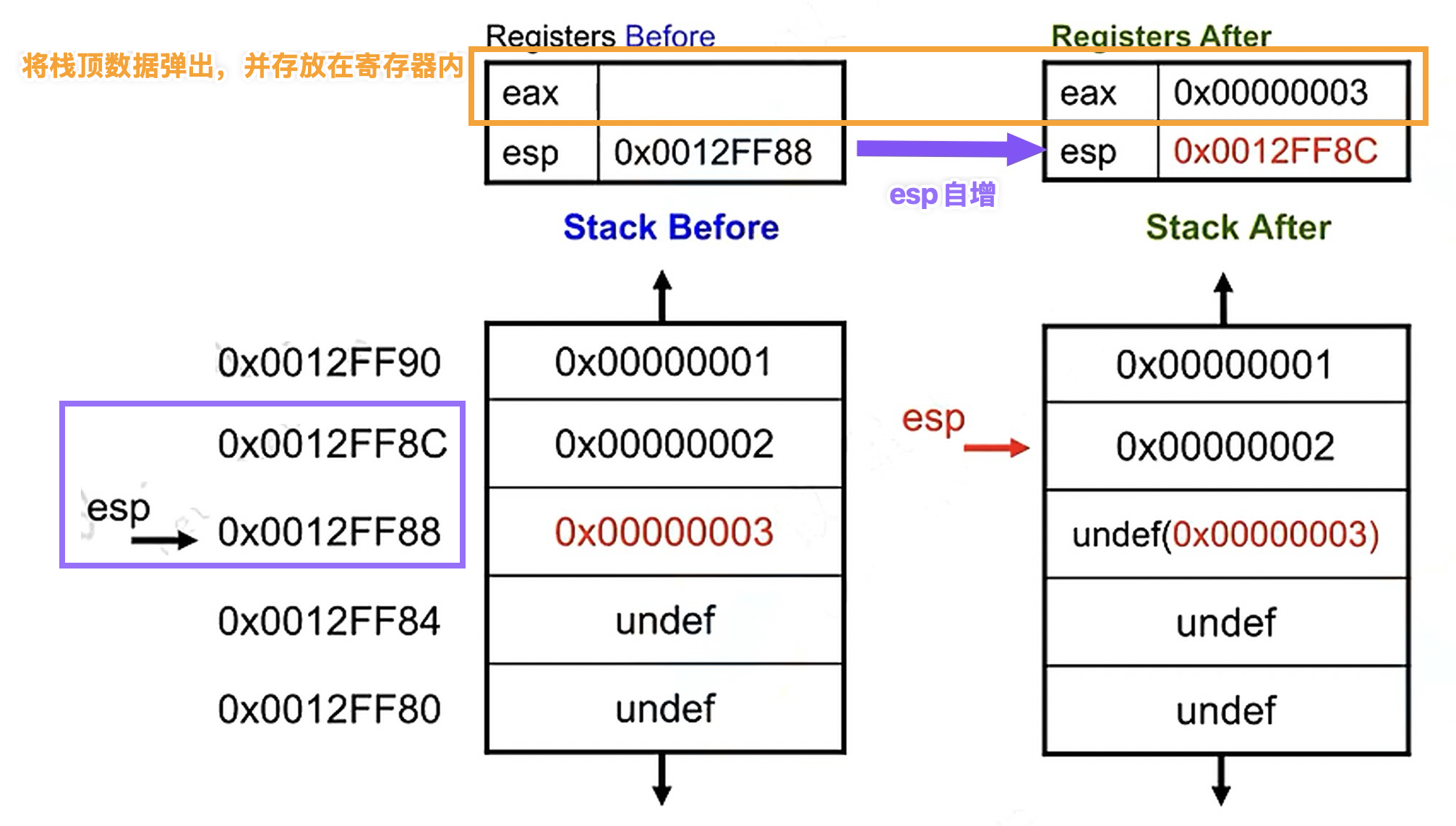 ⚠️Note: the stack data at
⚠️Note: the stack data at 0x0012FF88 here will not be cleared, but it will be overwritten during normal program execution.
MOV(mov)
The MOV instruction moves data from the source operand to the destination operand.
The instruction format is mov x1 (destination operand), x2 (source operand) Meaning data is moved from x2 to ×1. ×1 and ×2 can be:
- register to register
- memory to register, register to memory
- immediate to register, immediate to memory; cannot move directly from memory to memory.
Example:
LEA(lea)&
The LEA (load address) instruction is used to load an effective address. The instruction format is lea ×1,X2. x1 can be r16/32/64, x2 is a memory address, commonly written using the [] syntax, meaning dereference/evaluation. Commonly used for pointer arithmetic, and sometimes for numeric calculation. Example: ebx=0x2 edx=0×1000
ADD(add)
The ADD instruction performs addition. The instruction format is add×1,x2. x1 and x2 can be r/m16, r/m32, r/m64; x2 can also be an immediate value, but both operands cannot be memory operands at the same time. The result of the instruction affects the eflags register, modifying the OF, SF, ZF, AF, PF, and CE flags.
Example:
SUB(sub)
The SUB instruction performs subtraction.
The instruction format is sub ×1,X2。
×1 and ×2 can be r/m16,r/m32,r/m64, and ×2 can also be an immediate value, but both operands cannot be memory operands at the same time.
The result of the instruction affects the eflags register, modifying the OF, SF, ZF, AF, PF, and CF flags.
Example:
IMUL/MUL(iml/mul)
The IMUL instruction is used to perform signed multiplication.
Three instruction formats:
- imul r/m32 ;edx:eax=eax * r/m32
- imul reg, r/m32 ;reg =reg* r/m32
- imul reg, r/m32, imm ;reg =r/m32* imm
The MUL instruction performs unsigned multiplication.
IDIV/DIV(idiv/div)
The DIV instruction is used to perform unsigned division.
Two instruction formats
- Unsigned division, div ax.r/m8 ;ax divided by r/m8, al is the quotient, ah is the remainder
- Unsigned division, div ea& r/m32 ;edx:eax divided by r/m32, eax is the quotient, edx is the remainder If the dividend is a DWORD, edx is set to 0 before the instruction executes.
If the divisor is 0, a divide-by-zero exception is thrown.
AND(and)
Performs & (AND) The AND instruction performs a logical AND operation on the operands. The instruction format is and x1,x2. x1.x2 can be r/m16, r/m32, r/m64; x2 can also be an immediate value, but both operands cannot be memory operands at the same time.
OR(or)
Performs ^ (OR) The OR instruction performs a logical OR operation on the operands. The instruction format is orx1,x2. X1,x2 can be r/m16, r/m32, r/m64; x2 can also be an immediate value, but both operands cannot be memory operands at the same time.
XOR(xor)
Performs XOR The XOR instruction performs a logical XOR operation on the operands. The instruction format is xorx1,x2。 ×1 and x2 can be r/m16, r/m32, r/m64; x2 can also be an immediate value, but both operands cannot be memory operands at the same time.
Note: XOR is often used to clear a register, such as xor eex,eax, and is efficient.
NOT(not)
Performs ! (NOT)
SHL(shl)
Logical left shift
SHR(shr)
Logical right shift
JMP(jmp)
Unconditional jump, with three jump methods
JCC Set(jcc)
Conditional jumps
CMP(cmp)
The CMP instruction is used to compare the sizes of two operands. The instruction format is CWPX1.x2. cmp compares by subtracting x2 from x1, sets the corresponding eflags bits based on the subtraction result, and discards the subtraction result. cmp < —— > sub:
- performs subtraction in the same way and sets the eflags 奇 register in the same way
- but the sub instruction stores the calculation result in ×1, while the cmp instruction does not preserve the calculation result; the modified eflags 奇 register bits include CF, OF, SF, ZF, AF, PF.
TEST(test)
Protection Mechanisms
canary (stack canary)
NX
PIE and ASLR
| When writing ROP or shellcode, one unavoidable problem is finding function addresses. | |
| PIE means randomization of the program’s loaded base address in memory, which means we cannot determine the program’s base address immediately. | |
| ASLR is largely similar; ASLR randomizes the addresses of dynamically linked libraries, the stack, etc. at runtime. | |
| Generally speaking, PWN challenges in CTF most often deal with these two protections. | |
| The bypass method is to leak a function address, then determine the base address through the function’s offset. |